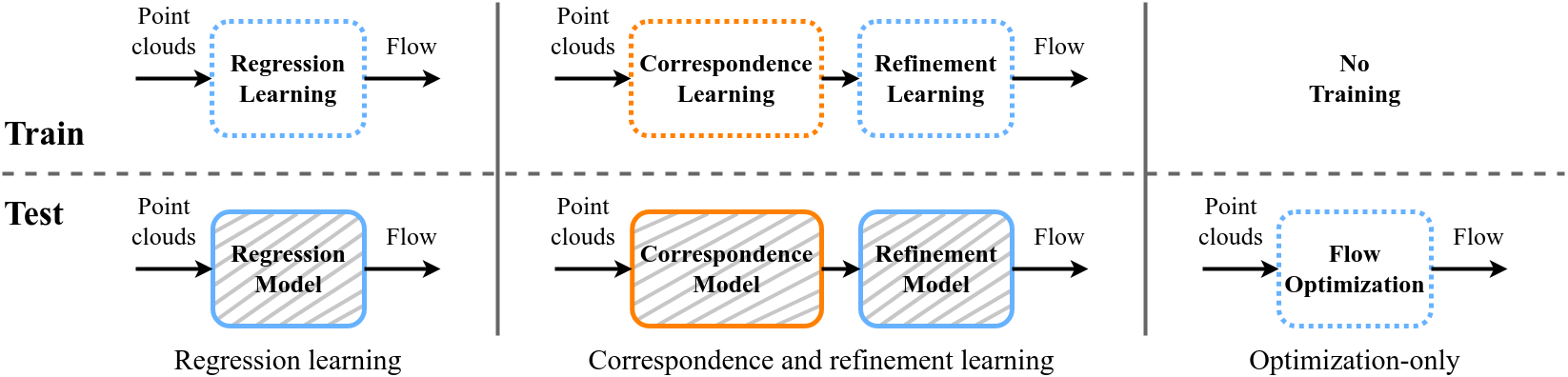
Scene flow estimation is a long-standing problem in computer vision, where the goal is to find the 3D motion of a scene from its consecutive observations. Recently, there have been efforts to compute the scene flow from 3D point clouds. A common approach is to train a regression model that consumes source and target point clouds and outputs the per-point translation vector. An alternative is to learn point matches between the point clouds concurrently with regressing a refinement of the initial correspondence flow. In both cases, the learning task is very challenging since the flow regression is done in the free 3D space, and a typical solution is to resort to a large annotated synthetic dataset.
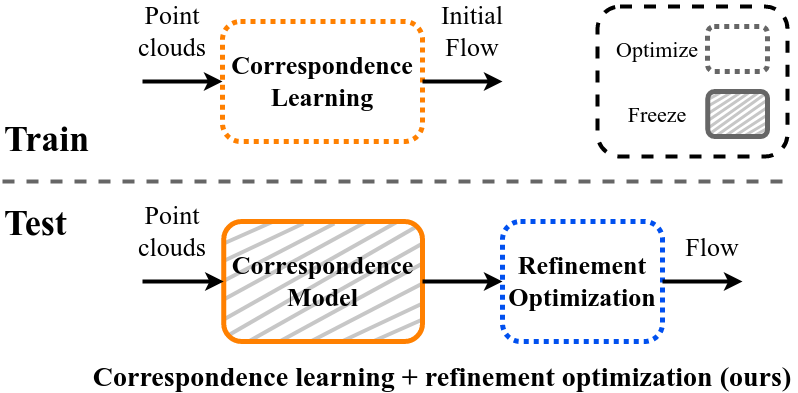
We introduce SCOOP, a new method for scene flow estimation that can be learned on a small amount of data without employing ground-truth flow supervision. In contrast to previous work, we train a pure correspondence model focused on learning point feature representation and initialize the flow as the difference between a source point and its softly corresponding target point. Then, in the run-time phase, we directly optimize a flow refinement component with a self-supervised objective, which leads to a coherent and accurate flow field between the point clouds. Experiments on widespread datasets demonstrate the performance gains achieved by our method compared to existing leading techniques while using a fraction of the training data.
Previous methods regress the entire flow in the ambient 3D space, jointly learn correspondence and refinement, or optimize the complete flow from scratch separately for each scene. Instead, we replace these challenging problems with two simpler ones: training a correspondence model focused only on learning point feature representation without any flow regression, and directly optimizing a residual flow refinement at the run-time.
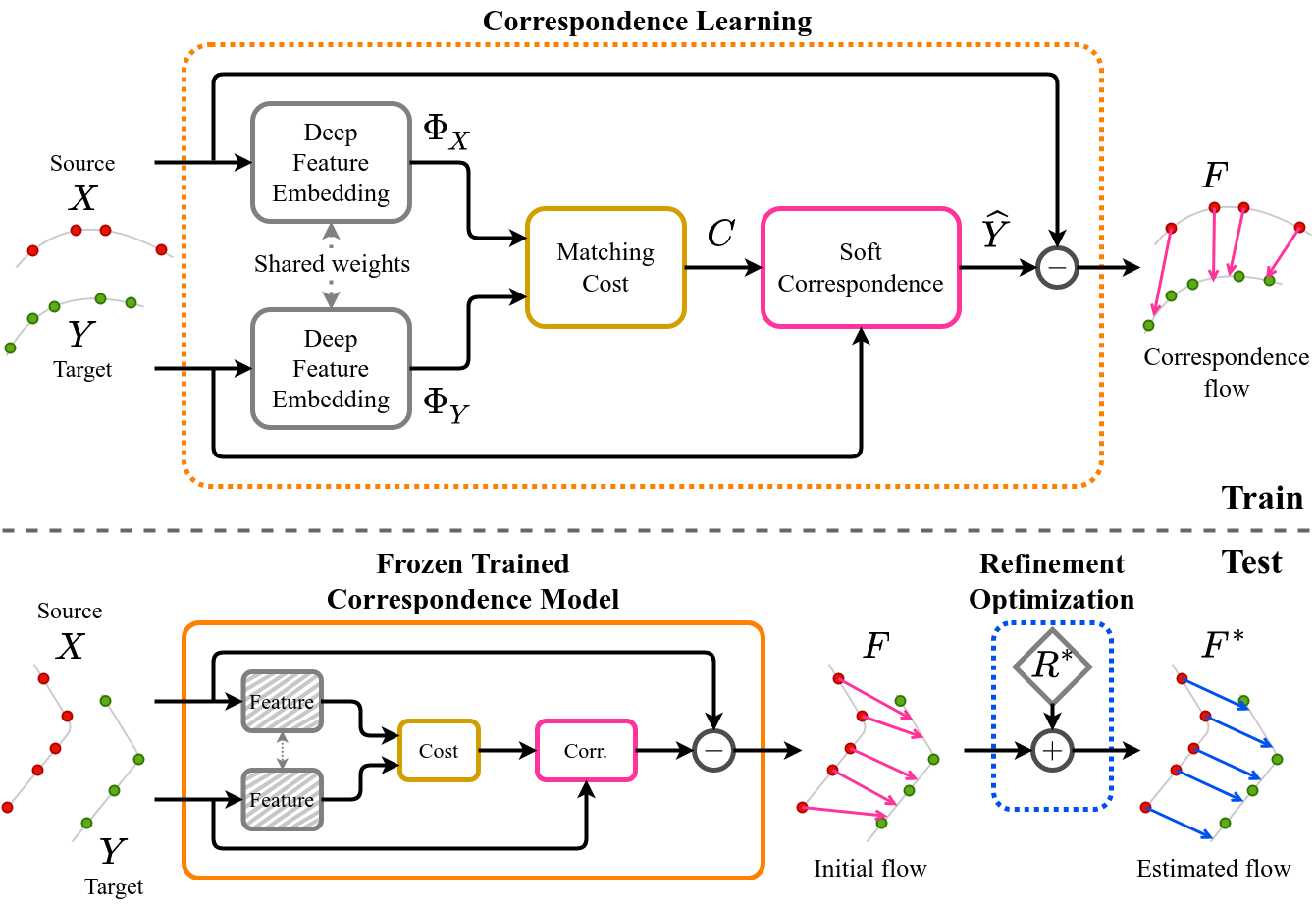
SCOOP includes two components: a learned point cloud correspondence model and a flow refinement module. The model is focused on learning deep point embeddings φX, φY to establish soft point matches based on a matching cost C in the latent feature space. The initial flow F from the training phase is the difference between the softly corresponding point cloud and the source point cloud.
At the test-time, we freeze the trained model and directly optimize a residual flow refinement R* to produce a smooth and consistent scene flow F* between the point clouds.
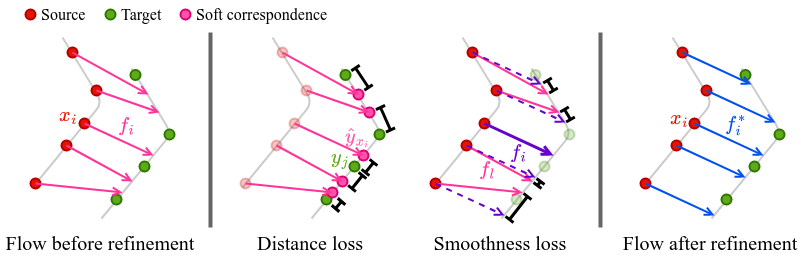
Our self-supervised losses require that each translated source point has a nearby target point and that neighboring source points have similar flow vectors. These two losses result in a coherent flow field that warps the source point cloud close to the underlying surface of the target point cloud.
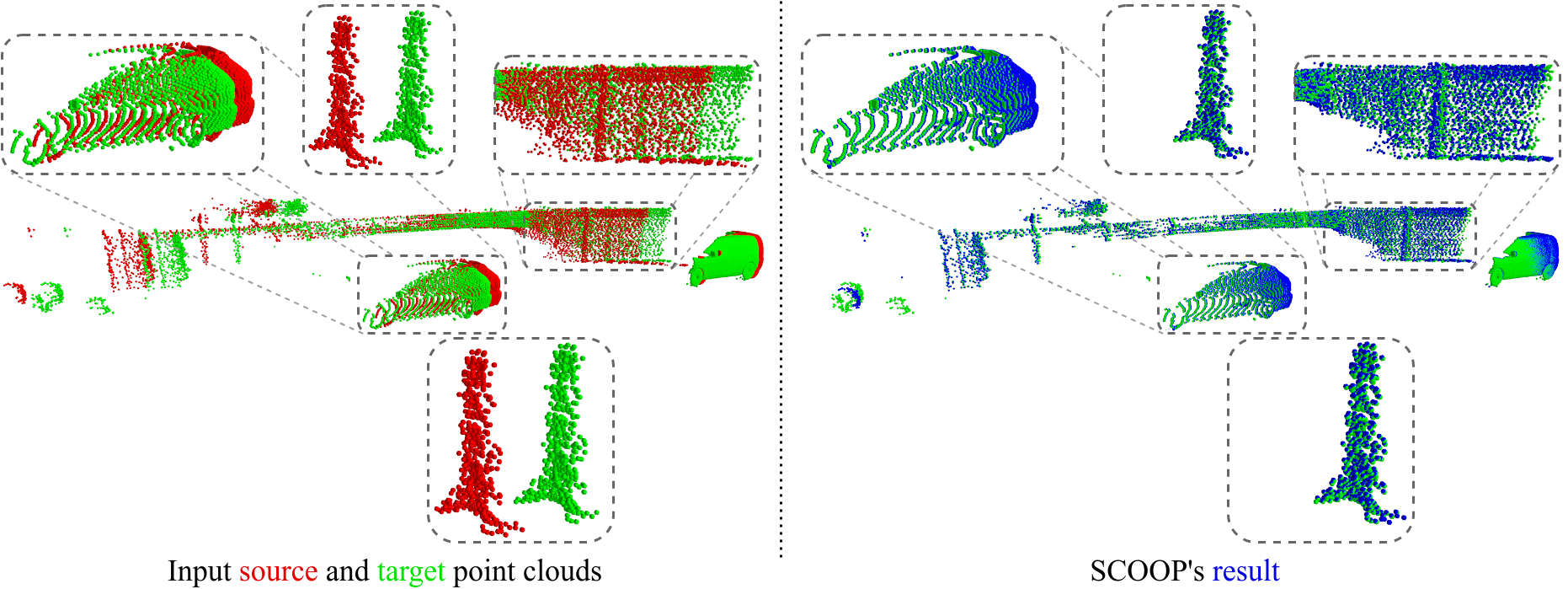
Compared to the popular previous method FLOT, SCOOP better preserves the structure of the source point cloud and accurately computes its flow.
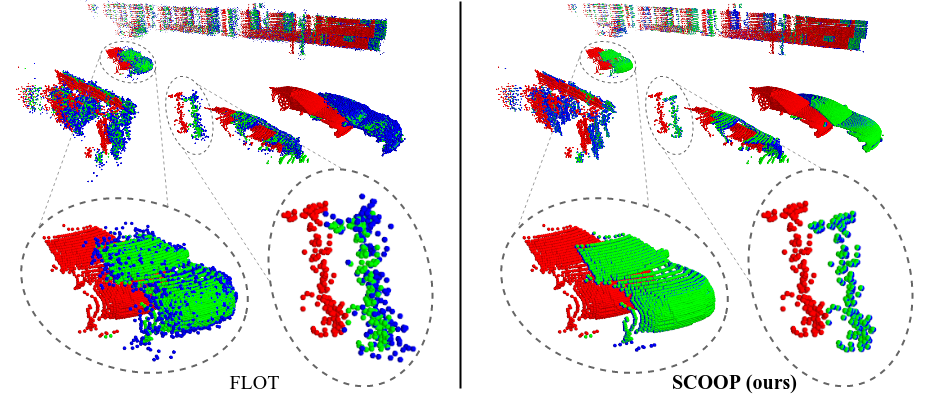
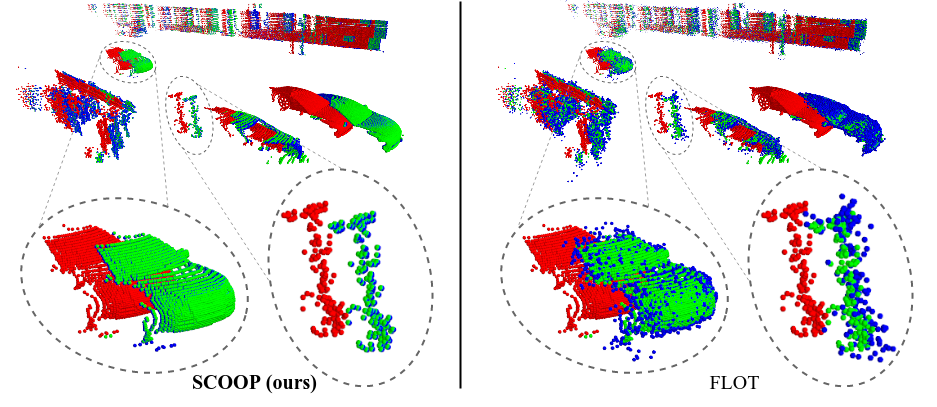
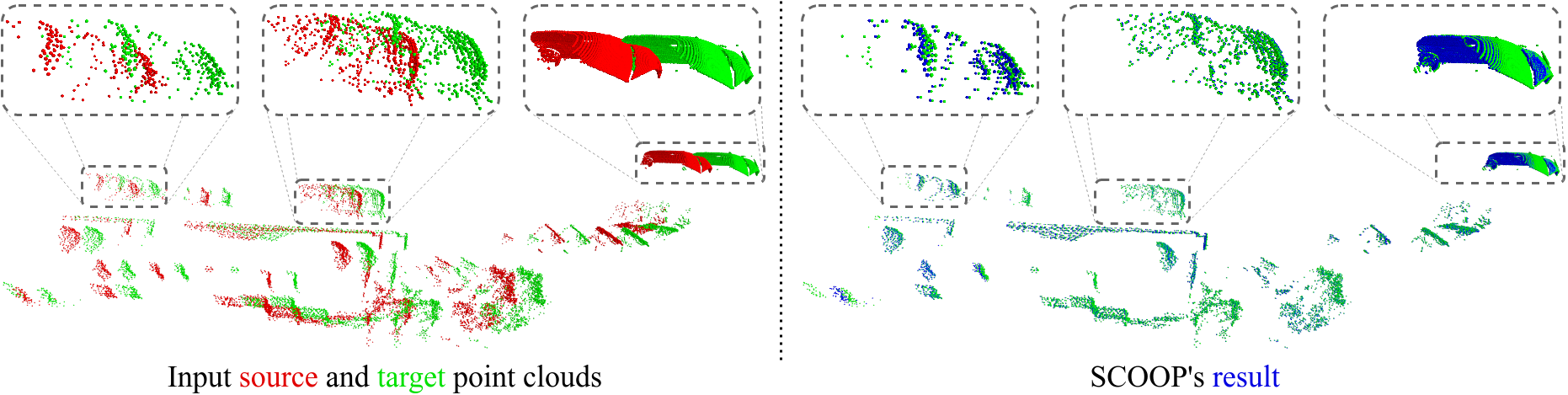
SCOOP estimates the scene flow correctly in various challenging cases:
Varied point cloud density (cars).
Repetitive structures (fence).
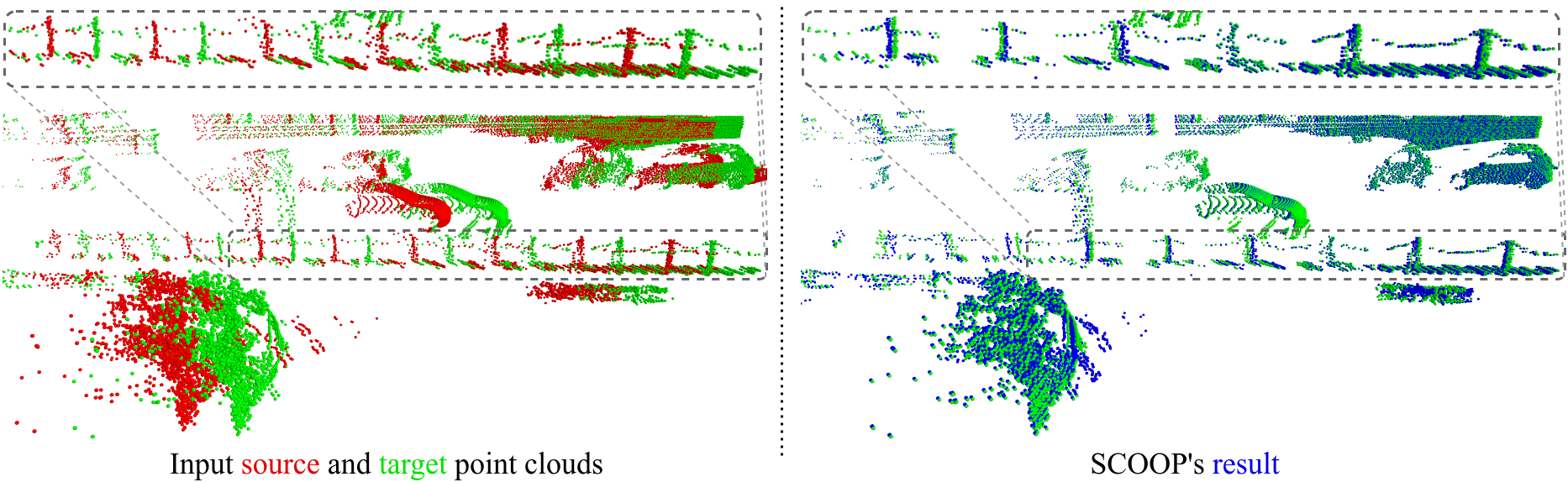
Objects with different motion directions (car and pole) or different geometry and size (pole and facade).
@InProceedings{lang2023scoop,
author = {Lang, Itai and Aiger, Dror and Cole, Forrester and Avidan, Shai and Rubinstein, Michael},
title = {{SCOOP: Self-Supervised Correspondence and Optimization-Based Scene Flow}},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
pages = {5281--5290},
year = {2023}
}




